2. System architecture
Architecture comes first. Decide on the data model, endpoint shape, auth strategy, and deployment target before you write code. Decisions made here cascade through every later phase.
The walked example is a news intelligence platform: aggregates articles from NewsAPI, the Guardian, and Reddit; stores them in PostgreSQL; caches the merged result set in Redis; exposes everything through a FastAPI REST API with Reddit OAuth for user accounts, saved articles, and search history.
The work the platform does between "fetch from three sources" and "return JSON" is where the architecture earns its complexity: cache lookups before any external call, parallel fan-out across the three APIs when the cache misses, deduplication of the same story coming back from multiple sources, relevance scoring, and per-user history. Each of those needs a place to live; the next sections lay out where.
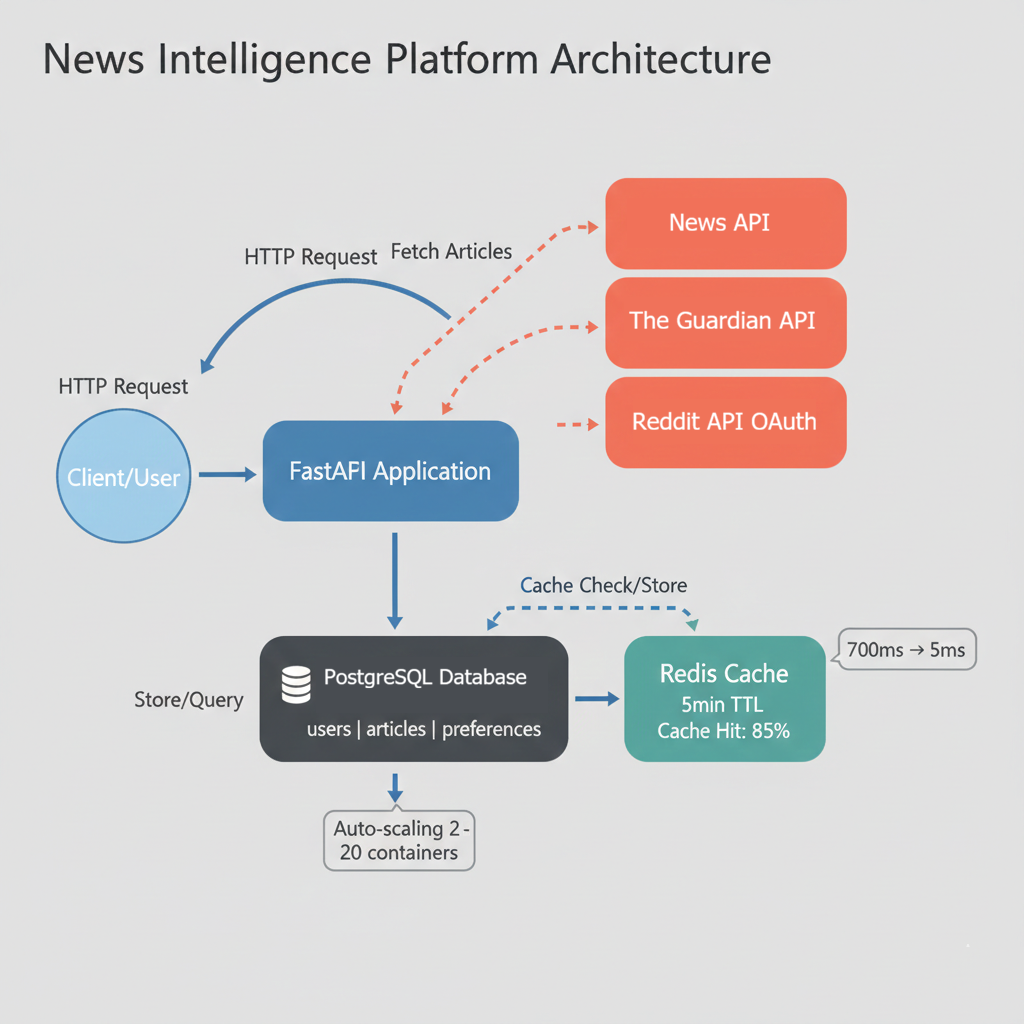
High-level architecture
Six components, each with one responsibility:
- FastAPI application (the orchestrator). Receives requests, fans out to the external APIs in parallel via
asyncio.gather(), normalises the three response shapes into one, deduplicates, writes through to PostgreSQL, populates Redis, returns the response. This is where the chapter's logic lives. - External APIs (the data sources). NewsAPI (international news, API key in a header), the Guardian (long-form journalism, API key as a query parameter), Reddit (community submissions, OAuth 2.0 bearer token). Three different auth shapes, three different response shapes, three different reliability profiles -- the per-source client classes in section 3 absorb all of that so the rest of the application sees one article shape.
- PostgreSQL (the persistent store). Holds users, articles, preferences, search history, and saves. The schema also flattens the source-shape differences: NewsAPI's
source.name, the Guardian'ssectionName, and Reddit'ssubredditall land in onesourcecolumn. Foreign keys keep referential integrity tight, and the full-text index on title plus description supports queries the external APIs can't answer at all (search across all three sources at once, look back further than each source's retention window, "more like this" off the user's saved articles). - Redis (the performance layer). Caches merged external API responses with a 5-minute TTL, caches expensive database query results, stores per-user rate-limit counters, and holds session data for authenticated users. A cache hit serves the merged result set straight from memory in roughly 5ms; a miss fans out to all three external APIs in parallel and ends up around 800ms. The 5-minute TTL is the freshness-vs-call-budget tradeoff: long enough that most repeated queries stay in cache, short enough that news doesn't go stale.
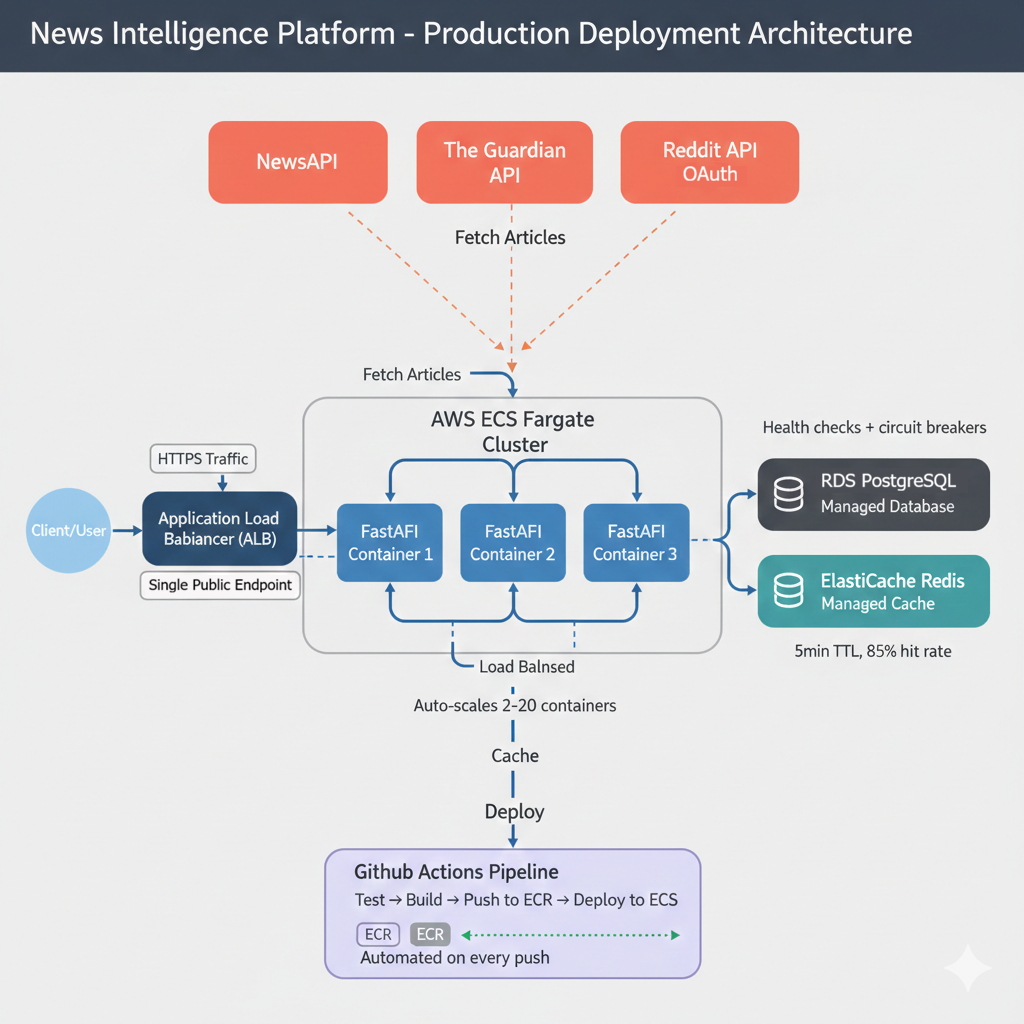
- AWS infrastructure (the production platform). ECS Fargate runs the application containers; the target-tracking auto-scaling policy holds CPU near 70% by scaling between 2 and 10 tasks. RDS PostgreSQL handles backups, point-in-time recovery, and Multi-AZ failover. ElastiCache Redis provides the cache with replication. An Application Load Balancer fronts the cluster and gives the system a stable public endpoint. CloudWatch holds the dashboards, alarms, and logs from every layer.
- GitHub Actions (the deployment pipeline). Every push to
mainruns pytest with coverage reporting, builds the Docker image as a multi-stage build tagged with the commit SHA, pushes the image to ECR, registers a new ECS task definition revision, updates the service, and waits for health checks. If the new tasks fail health checks the deployment circuit breaker rolls back to the previous revision. The same sequence runs identically every time, gated by the test result; the manual sequence from Chapter 28 still works, it just isn't the path the team has to take.
Each component could be swapped (FastAPI with Flask, PostgreSQL with MySQL, ECS with Kubernetes) without changing the shape: external integration, persistent storage, performance caching, scalable deployment, automated operations. The chapter walks a specific instantiation, but the substrate is what travels.
Request flow: what happens when a user searches
A user searches for "artificial intelligence" and the response comes back in around 5ms on a cache hit or around 800ms on a miss. The path through the components is the same either way until the cache lookup; that's where it forks.
- User requests articles. Browser sends
GET /articles?q=artificial+intelligence&limit=20to your Application Load Balancer's public URL (something likenews-api-123456789.us-east-1.elb.amazonaws.com). The ALB checks which ECS tasks are healthy using health check endpoints (GET /healthmust return 200 OK). It forwards the request to a healthy task. If all tasks are unhealthy, the ALB returns 503 Service Unavailable. - Check cache first. Your application generates a cache key from the query parameters:
articles:q=artificial+intelligence:limit=20. It checks Redis usingGET articles:q=artificial+intelligence:limit=20. If cached (Redis returns data): Return immediately. Response time: ~5ms. The data includes articles from all three sources, already deduplicated and sorted. If not cached (Redis returns null): Continue to step 3. Response time will be ~800ms (external API calls + processing + caching). - Fetch from external APIs (parallel). The application makes three simultaneous requests using
asyncio.gather(), saving roughly 600ms compared to sequential. NewsAPI hitsGET https://newsapi.org/v2/everythingwith the API key in a header; Guardian hitsGET https://content.guardianapis.com/searchwith the API key in a query parameter; Reddit hitsGET https://oauth.reddit.com/r/technology/searchwith an OAuth token in a header. Each API returns a different JSON shape (articles[]vsresponse.results[]vsdata.children[]); the per-source client classes (NewsAPIClient,GuardianAPIClient,RedditAPIClient) normalise each one to the same internal shape (title,description,url,source,published_at,image_url). - Deduplicate and merge. Articles about the same event appear in multiple sources ("OpenAI releases GPT-5" appears in NewsAPI, Guardian, and Reddit). Your deduplication logic compares titles using fuzzy matching (Levenshtein distance algorithm). If two titles are more than 80% similar they count as duplicates; the merge keeps the article with the most complete metadata (description, image, content) and mark duplicates as references. After deduplication, 60 articles from three sources become 35 unique articles.
- Store in PostgreSQL. New articles are inserted into the
articlestable with source attribution (source='newsapi'). Existing rows (identified by URL usingON CONFLICT (url) DO UPDATE) get a refreshedfetched_attimestamp instead of a duplicate row. Over time this builds an archive that outlives the external APIs' own retention windows. The GIN full-text index on title plus description plus content is what makes queries like "all articles mentioning 'machine learning' OR 'neural networks'" stay fast as the table grows. - Cache the results. Store the merged, deduplicated result set in Redis with a 5-minute TTL using
SETEX articles:q=artificial+intelligence:limit=20 300 [JSON]. This key expires automatically after 300 seconds, ensuring fresh data without manual invalidation logic. The next 50 requests for the same query hit the cache, serving results in 5ms instead of 800ms. Cost savings: 50 requests × 3 external APIs = 150 external API calls avoided. - Return response. Your API returns a JSON array of articles with unified schema and the counts the client needs:
{"articles": [...], "total": 35, "limit": 20}. (If you take on the stretch goal of full pagination from the evaluation page,pageandhas_morefields are the natural extension.) The client doesn't need to know which external API provided which article. That complexity is hidden. The response is consistently structured whether data came from cache (5ms) or external APIs (800ms). - Track analytics (async). After responding, a FastAPI background task records this search in the
search_historytable:INSERT INTO search_history (user_id, query, results_count) VALUES ($1, $2, $3). This doesn't delay the response. It happens asynchronously after the HTTP response is sent. Analytics enable features like "trending searches" (most common queries in past 24 hours) and "personalized recommendations" (articles similar to your search history).
The shape of the flow is why each component earns its place. Redis collapses the repeated-query case to a single in-memory read. PostgreSQL outlives the external APIs' retention windows, so historical queries don't depend on their archives. The application layer is where normalisation, deduplication, and TTL policy live; the request never sees those tradeoffs because the response shape is the same whether the data came from cache or from a 600ms fan-out.
Database schema design
Five tables: users, articles, user_preferences, saved_articles, search_history. Foreign keys with ON DELETE CASCADE keep referential integrity tight (delete a user, their preferences and saves go with them); indexes are sized to the queries that actually run (sort by published_at DESC, full-text search on title || description, look up saves by user_id). The user_preferences table is deliberately key-value so adding a new preference type doesn't need a migration. Treat the DDL on this page as a first-pass design sketch whose job is to argue the design decisions; the schema.sql you build against lives in section 3, which refines some of these choices, and where the two differ, section 3 is the canonical version.
- users table: authentication and session state. Holds the Reddit OAuth credentials plus session metadata. After a user completes Reddit's OAuth flow you store their Reddit user ID (unique), username, the access token, the refresh token, and the access token's expiry. Access tokens last an hour; the refresh token is what lets you mint a new one without bouncing the user through the OAuth flow again.
CREATE TABLE users (
id SERIAL PRIMARY KEY,
reddit_user_id VARCHAR(255) UNIQUE NOT NULL, -- From Reddit OAuth
username VARCHAR(255) NOT NULL,
access_token TEXT, -- Encrypted in production
refresh_token TEXT, -- Encrypted in production
token_expires_at TIMESTAMP,
created_at TIMESTAMP DEFAULT NOW(),
last_login_at TIMESTAMP
);Storing the OAuth tokens at rest trades security against UX. Persisted tokens mean users stay signed in for weeks; a database compromise also exposes those tokens. For local development plaintext is fine; before deploying to production the tokens should be encrypted via a key-management service (AWS KMS or Secrets Manager are the obvious fits).
- articles table: unified article storage across sources. One row per article regardless of which API it came from. The
sourcefield tags the origin (newsapi,guardian,reddit),external_idholds whatever ID the source uses, andurlcarries a UNIQUE constraint so refetching the same article over time updates the existing row instead of duplicating it.
The full-text index on title || ' ' || description || ' ' || COALESCE(content, '') is what makes queries like WHERE to_tsvector('english', title || ' ' || description) @@ plainto_tsquery('artificial intelligence') stay sub-50ms as the table grows into the millions of rows. It's a GIN index (Generalized Inverted Index); it's the PostgreSQL primitive that's built for tokenised text matching, in the same way a B-tree is built for ordered scans.
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
external_id VARCHAR(500) UNIQUE, -- Source-specific ID
title VARCHAR(500) NOT NULL,
description TEXT,
content TEXT, -- Full article text when available
url TEXT UNIQUE NOT NULL,
source VARCHAR(50) NOT NULL, -- 'newsapi', 'guardian', 'reddit'
author VARCHAR(255),
image_url TEXT,
published_at TIMESTAMP NOT NULL,
fetched_at TIMESTAMP DEFAULT NOW()
);
-- Performance indexes
CREATE INDEX idx_source ON articles (source);
CREATE INDEX idx_published_at ON articles (published_at DESC);
-- Full-text search
CREATE INDEX idx_fulltext ON articles USING GIN(
to_tsvector('english', title || ' ' || description || ' ' || COALESCE(content, ''))
);External APIs don't persist their results forever. NewsAPI's free tier is bounded to the past 30 days; the Guardian charges for the older archive; Reddit's search window is a few weeks. Storing every article that passes through makes the system's own corpus the authoritative one for historical queries, "more like this" recommendations against the user's reading history, and graceful degradation when one of the upstream APIs is down.
- user_preferences table: per-user settings. A key-value table, deliberately. Preferences are stored as rows with a
preference_keyand apreference_valuerather than columns; adding a new preference type is an insert, not a migration. Thepreference_valuecolumn is JSON when the value is structured ({"sources": ["newsapi", "guardian"], "excluded_topics": ["sports"]}) and a plain string when it isn't.
CREATE TABLE user_preferences (
id SERIAL PRIMARY KEY,
user_id INTEGER REFERENCES users(id) ON DELETE CASCADE,
preference_key VARCHAR(100) NOT NULL, -- 'preferred_sources', 'topics', 'language'
preference_value TEXT NOT NULL, -- JSON for complex preferences
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW(),
UNIQUE(user_id, preference_key)
);- saved_articles table: user bookmarks. A many-to-many join between users and articles. Users can save articles for later, and an article can be saved by many users. The
UNIQUE(user_id, article_id)constraint prevents duplicate saves. Thenotescolumn lets users add a free-text annotation alongside the bookmark.
CREATE TABLE saved_articles (
id SERIAL PRIMARY KEY,
user_id INTEGER REFERENCES users(id) ON DELETE CASCADE,
article_id INTEGER REFERENCES articles(id) ON DELETE CASCADE,
saved_at TIMESTAMP DEFAULT NOW(),
notes TEXT, -- User can add personal notes
UNIQUE(user_id, article_id)
);
CREATE INDEX idx_user_saved ON saved_articles (user_id, saved_at DESC);- search_history table: analytics and recommendations. One row per search. The table backs three features the chapter sketches: trending searches across the platform (
GROUP BY query ORDER BY COUNT(*) DESCover the last 24 hours), related searches per user, and personalised recommendations off the user's own history. It grows fast on an active deployment; in production you'd partition by date or archive rows beyond a retention window.
CREATE TABLE search_history (
id SERIAL PRIMARY KEY,
user_id INTEGER REFERENCES users(id) ON DELETE CASCADE,
query TEXT NOT NULL,
results_count INTEGER,
searched_at TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_user_searches ON search_history (user_id, searched_at DESC);
CREATE INDEX idx_popular_queries ON search_history (query, searched_at DESC);Two of these design choices are worth calling out because they're easy to get wrong.
Why separate user_preferences instead of a JSON column on users? Adding a new preference type doesn't need an ALTER TABLE; you insert a new row with a new preference_key. Querying across users for a single preference ("which users prefer the Guardian?") stays an indexed WHERE preference_key = 'preferred_sources' AND preference_value LIKE '%guardian%' rather than a JSON-path query. A JSON column on users is fine if preferences are write-only state; once you need to query across them, the join table wins.
Why INDEX (published_at DESC) rather than ASC? Because the dominant query is ORDER BY published_at DESC LIMIT 20 -- "the latest 20 articles" -- and a descending index serves that without an explicit sort step. If the dominant query were "the oldest articles first," the index would point the other way.
Next, in section 3, we move from the diagram to the codebase: scaffold the FastAPI app, wire up SQLAlchemy against the five-table schema, and build the three per-source client classes that absorb NewsAPI, Guardian, and Reddit into one internal article shape.