Chapter 12: API Data Validation
1. Why validation, and why now
In this chapter you'll learn to reject bad data, not just survive it. At the end you'll have a three-layer validation pipeline (structure, content, business rules) written two ways: manually in Python, and declaratively using JSON Schema. You'll also build a hybrid pattern that combines them, and learn which validators belong at each architectural boundary.
At the end of Chapter 11, problems like whitespace-only titles surviving .strip(), malformed timestamps surviving safe_get, and future-dated stories slipping through remained -- none of them solvable by defensive programming. The News Aggregator does not crash on any of them. It ships them. This chapter is the discipline that closes them.
The image below shows what the pipeline looks like from end to end: each layer is a filter that rejects bad data before it reaches the user.
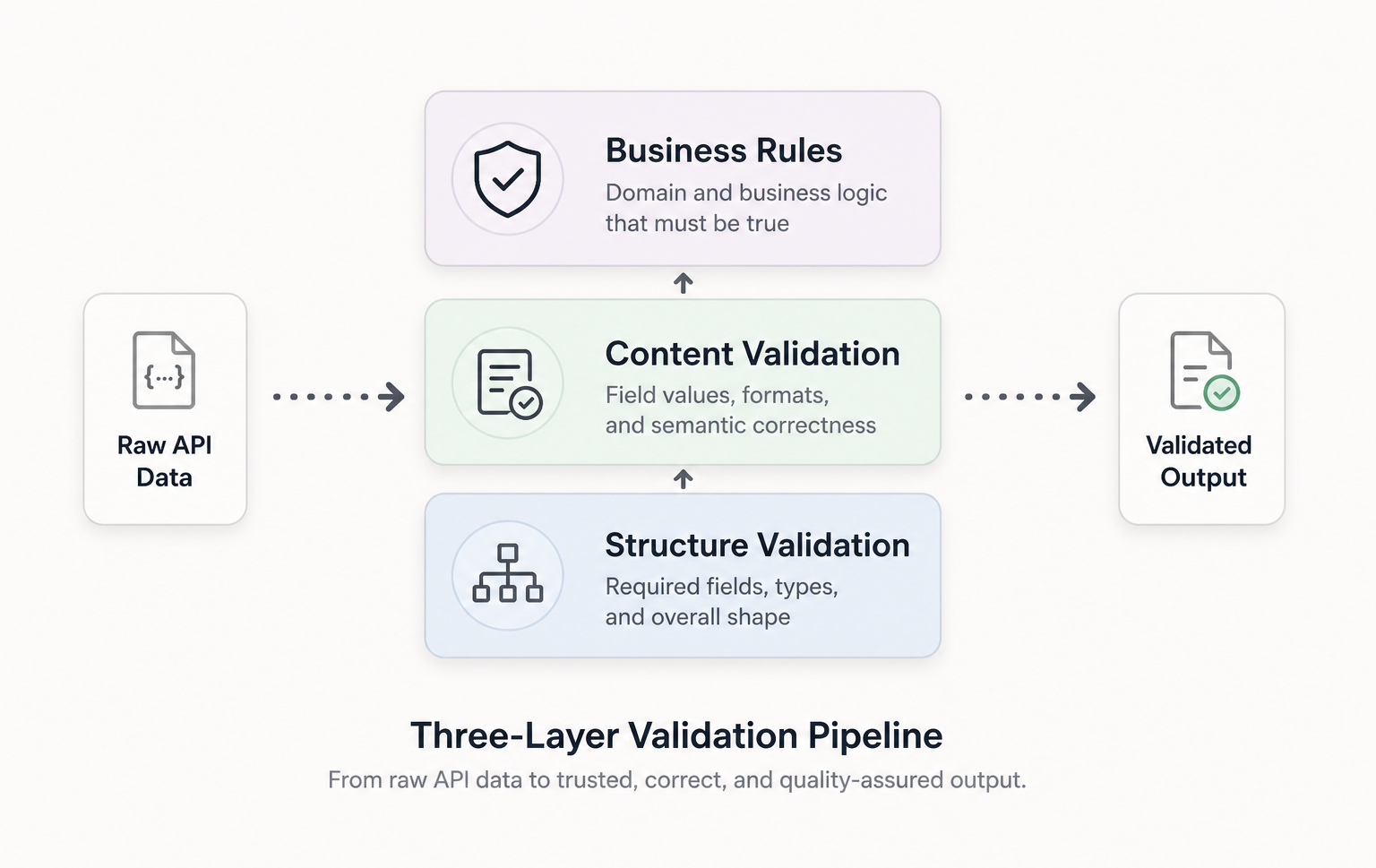
Defensive programming versus validation
Defensive programming prevents crashes. Validation prevents bad data. They are complementary and you need both, but they answer different questions and belong in different parts of your code. Defensive programming says "don't blow up when a key is missing." Validation says "a title of five spaces is not a title." Swap one for the other and you either crash on surprises you could have absorbed, or ship output no human would call correct.
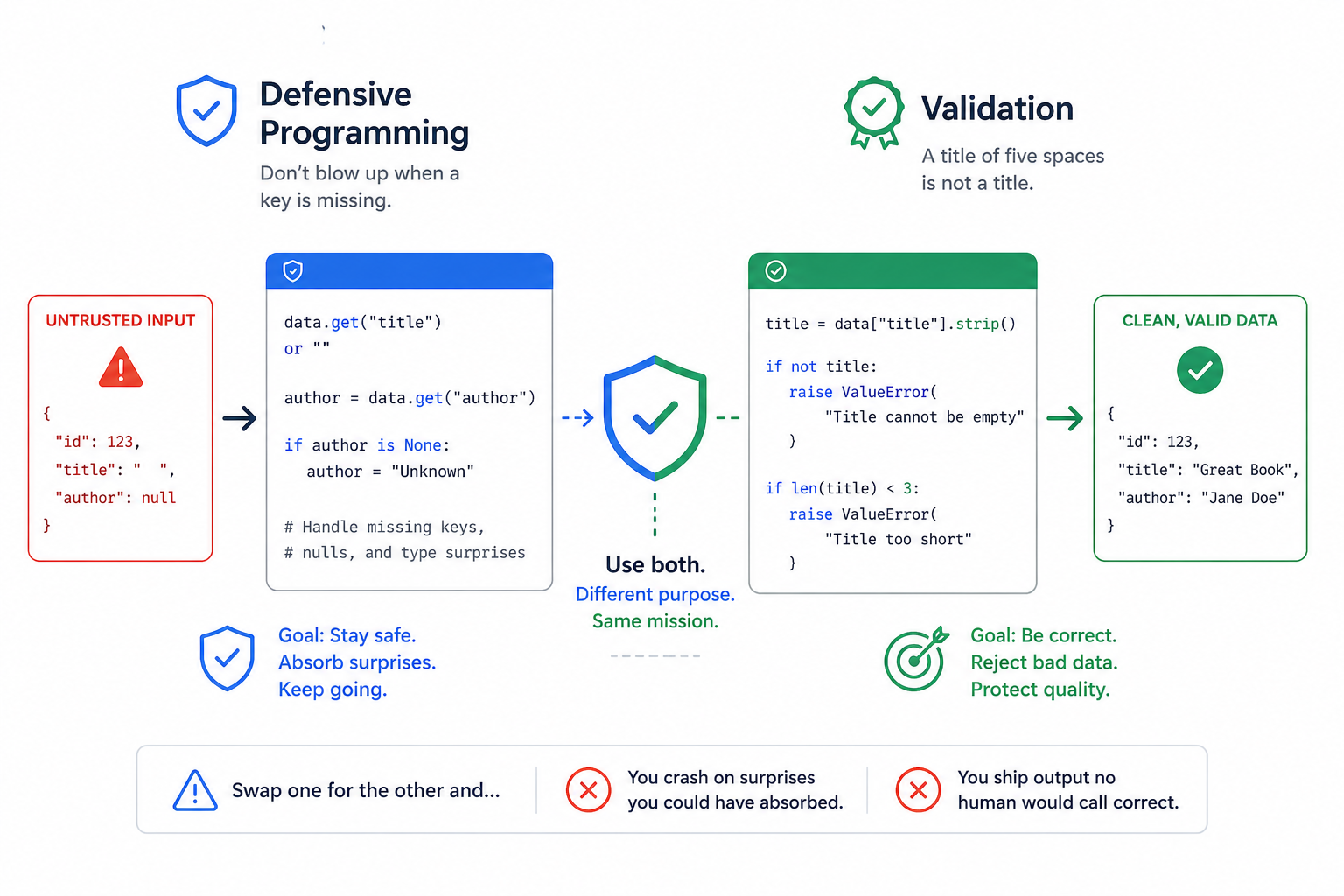
Chapters 9 to 11 built defensive programming: try/except around the network call, safe_get for nested access, try_fields for alternate key names, fallback values when a field is missing. Those patterns keep your application stable when data is missing, malformed, or unexpected. Validation, this chapter's subject, takes a stricter stance: the data has to meet a rule or it does not pass. If the temperature is -999, validation rejects it even though the type is fine and no exception was raised.
The News Aggregator illustrates the handoff. Defensive code inside each normalizer already prevents crashes on missing title or webPublicationDate fields. The output is never an exception. But "not an exception" is a long way from "correct." An article with a five-space title passes defensive checks and surfaces in the feed as blank. A timestamp the API sent as the string "null" survives try_fields and displays as "Invalid Date." Validation catches both before they reach the user.
The main examples use the Weather Dashboard from Chapter 8 because weather responses make structure, content, and business-rule failures easy to see in a small amount of code. The same pattern returns to the News Aggregator in the exercises, where you'll fix the empty-title bug directly.
Why add validation now
Three categories of problem keep surfacing in shipped applications, and defensive programming cannot reach any of them.
Silent corruption: fallback values hide quality issues that then leak into business logic. A missing author becomes ""; a malformed timestamp becomes "N/A"; users see corrupted data with no errors to debug.
Business requirements: some rules are not "nice to have" but load-bearing -- a payment amount must be positive, an email must contain @, a temperature must be physically possible. Defensive programming cannot express any of these.
Clear failures: when data does not meet a requirement, you want a specific rejection at the boundary, not silent corruption three modules downstream.
The answer is not "defensive programming or validation" but both, with each doing the work it is designed for. You keep the safe_get / try_fields / fallback pattern everywhere you handle external data. You add validation at specific boundaries where quality matters. The result is an application that is both resilient (handles unexpected situations without crashing) and reliable (produces trustworthy output).
What you'll learn
- Separate "safe" data (won't crash your code) from "valid" data (meets your requirements), and know when each discipline applies
- Implement three-layer validation (structural, content, business rules) as a sequential pipeline
- Write manual validators with clear error messages and fail-fast semantics that keep downstream code simple
- Use JSON Schema to declare structural and content rules once and run them with the
jsonschemalibrary - Combine schemas with manual functions in a hybrid approach that lets each one do what it is best at
- Place validation at the right architectural boundaries -- API client, service layer, application layer -- and test it systematically
What you'll build
validators.py-- three manual validator functions (structure, content, business rules) and thevalidate_weather_datapipeline that chains themweather_schema.json-- the same structural and content rules expressed as a JSON Schema, run throughjsonschema.validatehybrid_validate.py-- schema-first structural and content pass, followed by hand-written business-rule checksuser_validator.pyanduser_hybrid.py-- the end-of-chapter exercise: the same user-profile validator built first as three manual layers, then converted to the hybrid schema-plus-Python pattern from section 5forecast_validator.py-- a multi-day forecast validator with rules that span multiple fields (min <= max, array length parity)
Prerequisites
This chapter assumes you have the News Aggregator from Chapter 11 working, including the api_helpers.py toolkit from Chapter 10 (safe_get, try_fields, extract_items_and_meta) and the Article dataclass. Validation examples stand on top of that foundation -- the code blocks here assume from api_helpers import ... still works and do not redefine any of those helpers.
You also need the jsonschema library for sections 4 and 5. Install it with pip install jsonschema when you get there; earlier sections use only the standard library.